EXECUTIVE SUMMARYTo have a better understanding of each post and its sentiment, a topic was defined for each post and it is evident that some topics are likely to be more positive, while some are not. Since these topics are overlapping on words like "elderly" and "crow", those unique words will explain more for the topics. The average Pos-Neg Ratio of all posts is 1.64, while the ratio of Topic 4 (more about accusation) is only 1.13, compared to 3.94 for Topic 3 (more about improvement). Therefore, the topic is indeed a important feature to determine the sentiment of a post, which is proved in the following analysis. |
|
|||||||||||||
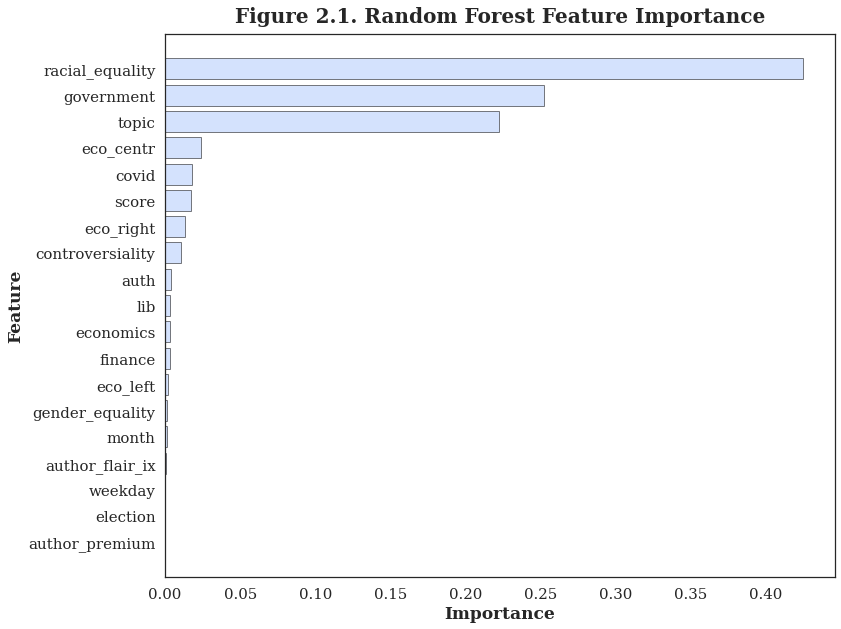
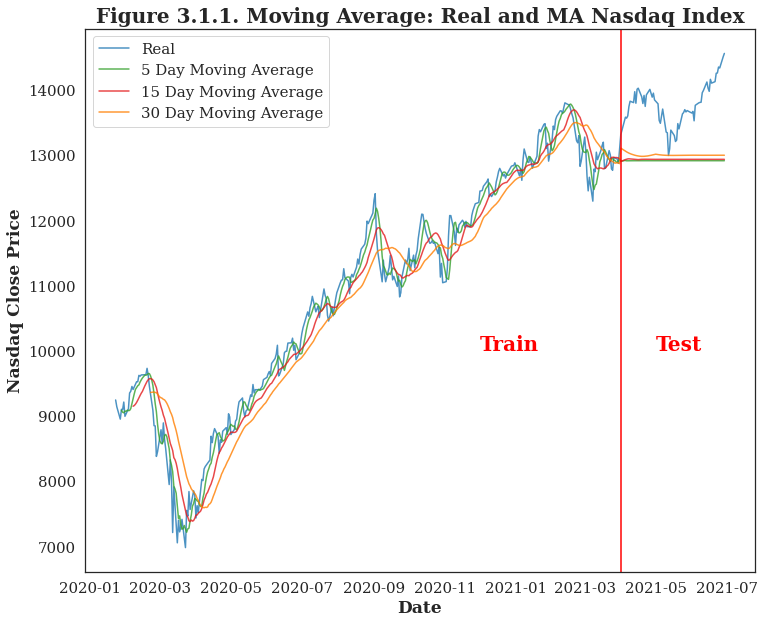
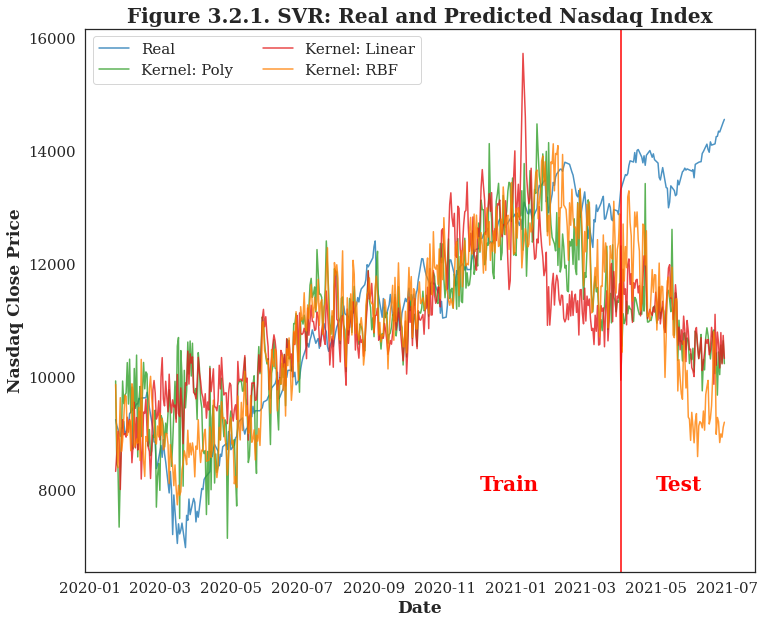
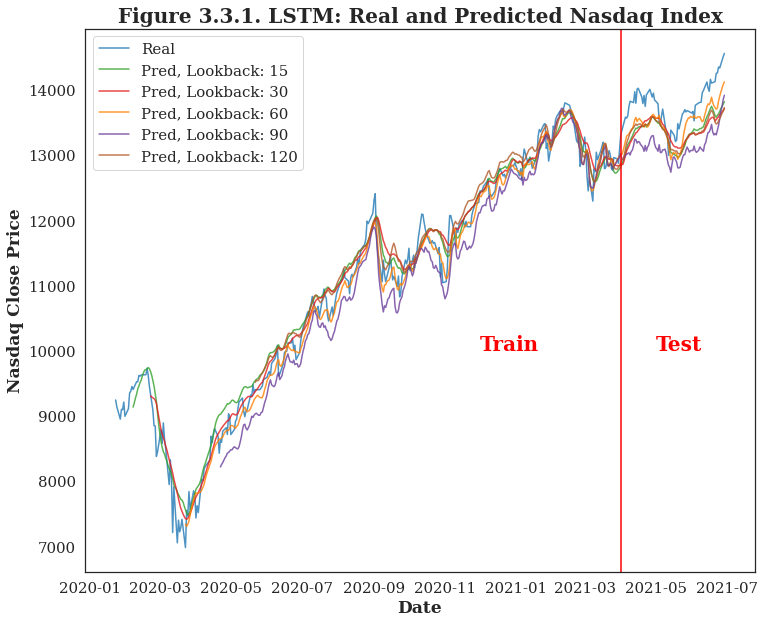
| Apart from the topic, whether the post is racial equality and government related or not is also the determinants of posts' sentiment. Since political factor is always an essential feature of stock market, these subreddit posts may have an impact on the stock prices. According to the time series plot of Nasdaq Index, the predictions is pretty close to the real close prices. And the best model uses the last 60 days' historical data to make a prediction of the next day price. | 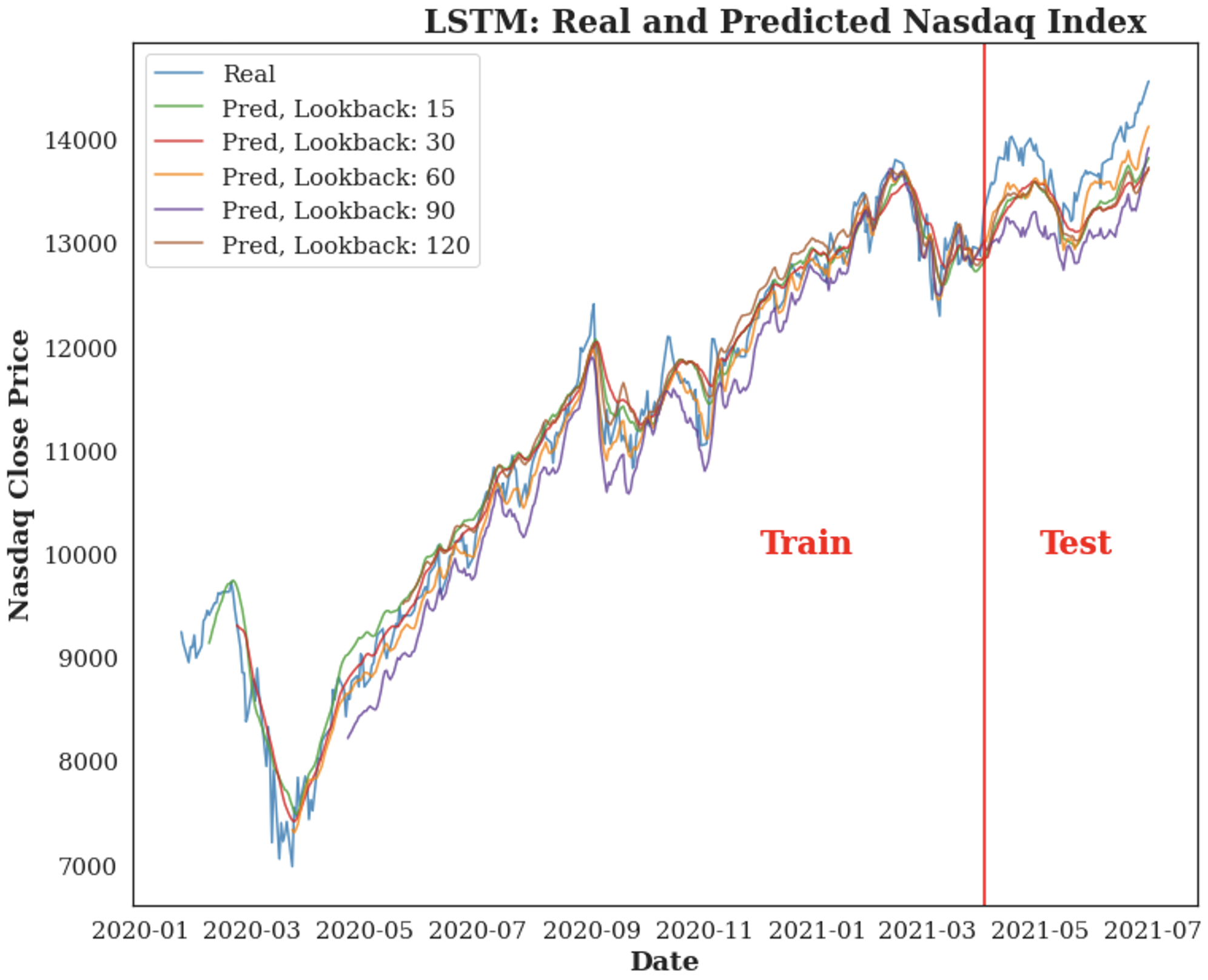 |
|||||||||||||
|
Topic Modeling - LDA
LDA, one of the most famous topic modeling methods was utilized here to define a topic for each post. It can be recognized that some specific topics tend to be more positive, while some are not. Some keywords appear in more than one topic, so those unique words will explain more for the topics. The average Pos-Neg Ratio of all posts is 1.64, while the ratio of Topic 4 (more about accusation) is only 1.13, compared to 3.94 for Topic 3 (more about improvement) |
|||||||||||||
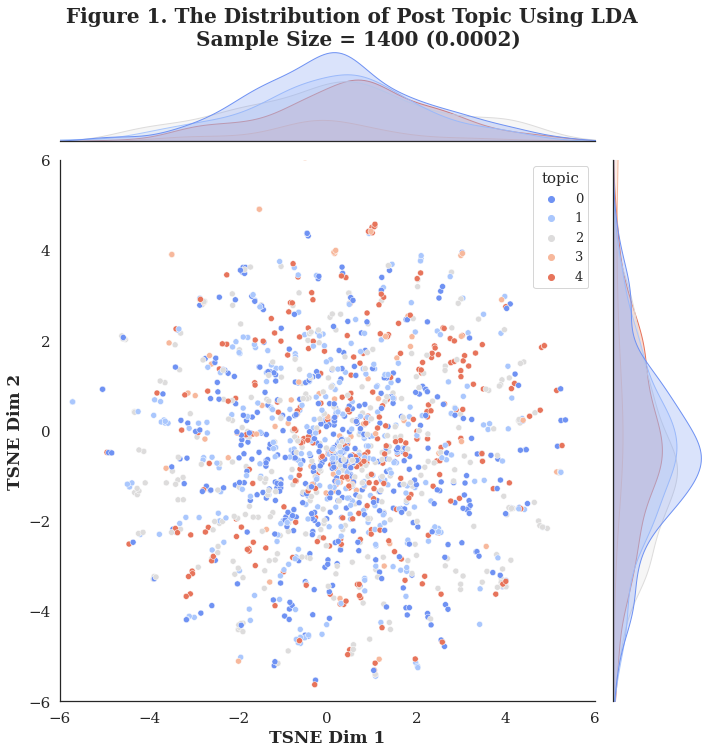 |
Normally Distributed on Each Dimension After defining topics for all the posts, it is necessary to know about the distribution of our topic to see if the model works well. Therefore, t-SNE, a tool to visualize high-dimensional data, was applied onto the results of TF-IDF to reduce the data to 2 dimensions, and these points were colored based on their topics. In agreement with the plot, each topic is normally distributed on these two dimensions, elucidating the successful seperation of LDA model. |
|||||||||||||



Sentiment Prediction
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
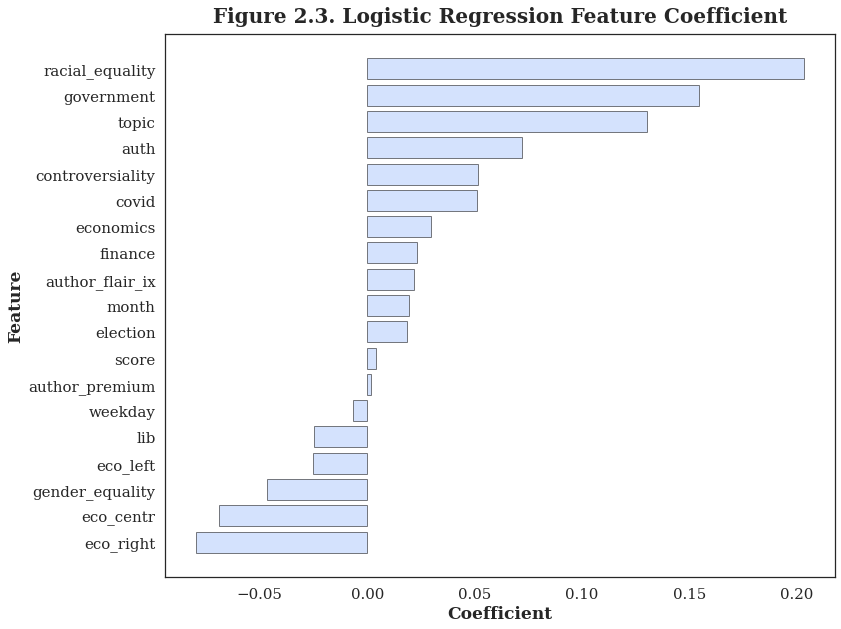
Racial Equality, Goverment and Topic In order to figure out the determinants of the sentiment for a post, the bar plots of feature importance were made for all these three simplest models, revealing that whether the post is racial equality and government related or not and its topic are the most important three determinants of a post's sentiment. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Stock Price Prediction
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
LSTM with 60 Days' Lag LSTM now can be proved to be able to defeat the moving average, and among all these choices of lookback days, 60 days' lag can provide enough information for the model to learn about the patterns and trends. When it is moving forward and getting farther away from the last training date, the predicted price will also get farther away from the true price |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Summary
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Resources |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
What's next?
Next section is Conclusions, we will summarize all the findings we have so far.